
解析ブースターは「大容量のデータファイルから、データ抽出を高速に行うCSV解析ツール」です。データベース化をせずに、大量のCSVファイルから必要なデータをダイレクトに高速抽出できます。処理できる時間が足らずあきらめていた大量のデータの解析が、データベースへのロード時間不要で可能になるため、研究開発やビジネス・アナリティクス等の業務効率向上にたいへん貢献します。

機能概要・特徴
「解析ブースター」は、CSVやテキストファイルをデータベース化せずに、必要なデータをダイレクトに簡易GUIやSQLで高速処理して、データの解析を可能にします。ビッグデータが注目されている昨今ですが、まだまだビジネスの現場ではデータベース化されていないデータが多数あります。 研究開発やビジネス・アナリティクス等の業務はもちろん、一般のビジネスでも大量のデータを取扱うシーンが多くなりました。データベースの知識がなくても、データ処理できるように、簡易GUIの操作だけでデータ抽出を可能にしています。もちろん、データベースに慣れた方にはSQLでの処理も可能で、定常業務に簡単に組み込むことも可能です。
また、部門業務で使用しているノートPCやデスクトップPCでも、数千~数億件規模のデータ抽出を高速に行えてしまえる点も大きな特長です。大量データの高速処理は、開発した「株式会社高速屋」が特許取得済みの高速ツリーアルゴリズムと、非同期I/Oによって実現しており、他社データベースとの比較ベンチマークテストでは、あるサプライヤー向け発注データ編集処理において、解析ブースターは他社データベースよりも14倍も速い結果を出しております。
特徴
Point 1”SQL+プロシージャ”によるCSVファイルへのダイレクト処理
“SQL + プロシージャ” を処理系として、高度で柔軟な処理記述が可能 実行環境として、スクリプトと標準API(ODBC/JDBC)を装備 しています。
Point 2大量データの高速処理
独自の高速ツリーアルゴリズム(特許取得済み)と非同期I/Oにより、ストレージの帯域幅をフル活用した高速データ処理が可能です。
Point 3省メモリ
一時ファイル作成による分割・結合(マージ)方式により、省メモリで動作します。
Point 4入力ファイルサイズが実用上無制限
テラバイト以上の入力データファイルを指定でき、実用上無制限に処理可能です。入力データファイルのサイズは製品価格に影響しません。
(※入出力のためのストレージ容量など、本製品の動作要件を満たすことが前提となります。)
機能
SQL/プロシージャ入力実行(Oracle PL/SQLベース)
簡易GUIで記述できないきめ細かな処理は、SQL,またはプロシージャの記述で柔軟に対応。これらの機能はクライアント機能あるいはODBCやJDBCを経由して実行することが可能であり、様々なアプリケーションから利用可能になります。
- バッチスクリプト化することで各種の日時処理、月次処理などの定型バッチ処理として組み込むことが可能になります。
- EXCELに組み込むことにより、使い慣れたEXCELを定型、非定型の帳票作成 ツールやBIツールとして活用することが可能です。
- IISやAPACHE等の標準インターフェースを利用したWEBアプリケーションからも ご利用できます。

スクリプトファイルの保存・実行
【EXCEL組込みの例】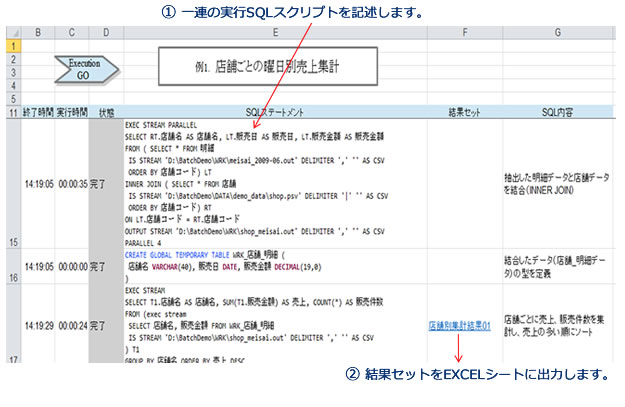
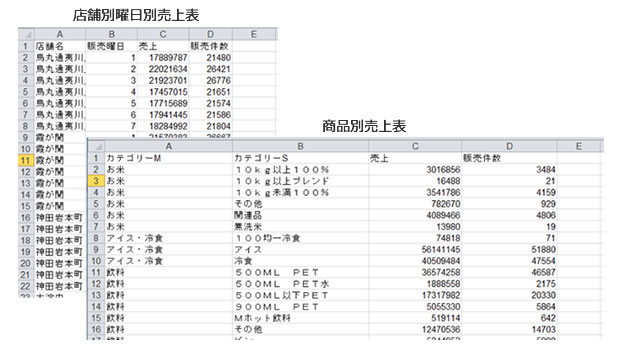
標準API(ODBC/JDBC)
並列処理(最大16並列まで)
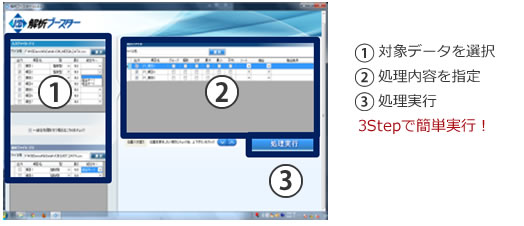
簡易GUIによるCSVファイル編集
簡単な簡易GUIにより結合・フィルタリング・ソート・集計操作
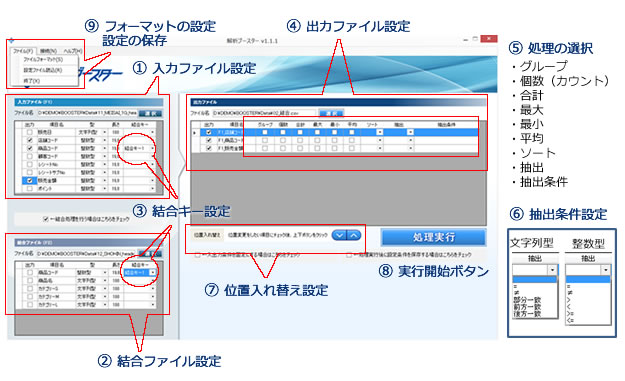
- ① 入力ファイルの設定
- 抽出対象のCSVファイルを選択できます。
また、同じ形式のファイルについては複数選択することで1つのデータファイルとしてまとめて処理することができます。(最大8ファイル) - ② ③ 結合ファイルと結合キーの設定
- 結合ファイルと結合キーを設定することで入力ファイルとデータを結合することができます。
- ④ ⑤ ⑥ 出力ファイル設定
- 入力ファイルと結合ファイルからどのような型式とレイアウトでデータを抽出するかを設定します。
<設定可能な項目条件>
グループ/個数(カウント)/合計/最大/最小/平均/ソート/抽出/抽出条件 - ⑦ 位置入れ替え設定
- 出力する項目の順番を変えることができます。
- ⑧ 実行ボタン
- ① から⑦で設定した処理を実行します
- ⑨ ファイルフォーマットの設定と保存
- 入力、出力ファイルのフォーマットを設定します。またその内容を保存します。
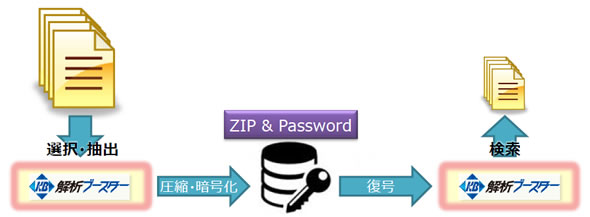
圧縮・暗号化入出力(簡易GUI利用時のみ)
CSVの処理結果を圧縮し、暗号化ファイル(ZIP形式)として出力
ZIPファイルの復号 ⇒ CSV編集をダイレクトに実行
データ解析の方法
解析ブースターによるデータ解析方法は、3つあります。
方法1スクリプト呼び出し
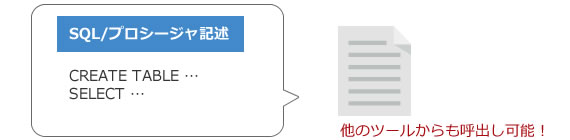
方法2標準API(ODBC/JDBC)
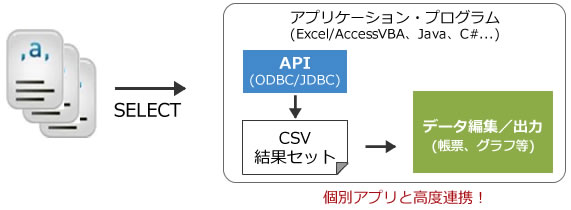
方法3標準API(ODBC/JDBC)
処理時間例

※Windows Server 2008は米国および/または他の国のMicrosoft Corporationの登録商標または商標です。IntelおよびXeonは、米国および/またはその他の国におけるIntel Corporationの商標です。なお、本文中には(TM)、(R)マークは明記しておりません。
利用例
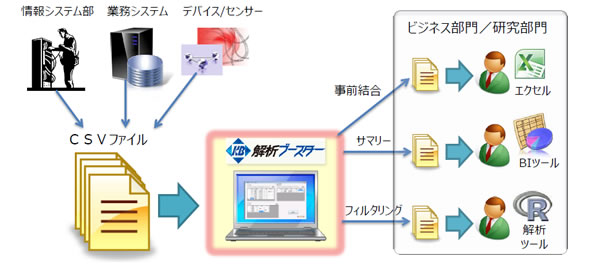
①エクセルやBIツール、解析ツール向けへのデータ抽出
様々な業務で集積されたデータを、集計やフィルタリングする際に大容量でも高速に処理して利用部門が必要なデータを抽出します。
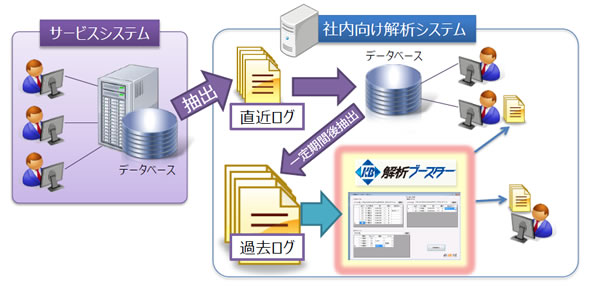
②大量ログの解析
アクセスログ等の大量に溜まった過去のログデータについて、集計や兆候分析等の処理時間の悩みを解決します。
③サーチャブルなエンコード・バックアップ
アクセスログ等の大量に溜まった過去のログデータについて、集計や兆候分析等の処理時間の悩みを解決します。
仕様・対応機種
| スペック | |
|---|---|
| CPU | Intel Xeon / Core i3 以降 |
| 主メモリ | 8 GB 以上 |
| ストレージ | 入力データファイルサイズの3倍以上の空き容量 |
| OS | Windows Server 2008(64bit)R2 / Windows 7 Home Premium(64bit) 以降 |
| モニター | WXGA(1280×800)以上 |
| インターフェース | USB2.0以降(ライセンスキー用) |
※Windows Server 2008、および Windows 7は米国および/または他の国のMicrosoft Corporationの登録商標または商標です。
なお、本文中には(TM)、(R)マークは明記しておりません。
