×


インシデント レスポンスとログ
セキュリティ インシデントが発生した場合、正常な状態に戻すための復旧活動が必要です。
適切なインシデントの対応を実施するための各フェーズについて、NIST(Recommendations of the National Institute
of Standards and Technology:米国国立標準技術研究所)のコンピュータセキュリティインシデント対応ガイドであるComputer Security Incident Handling Guide[Special Publication 800-61 Revision 2](以降、『NIST.SP.800-61r2』と呼ぶ)を基に、ログ管理との関係を見ていきます。
ログ管理の観点からも、当然ながらインシデント レスポンスには、各種システムのログの適切で有効な取り扱いが要となります。

(1) インシデント レスポンスとは?
昨今、セキュリティ上の脅威であるサイバー攻撃は、より多くの多様性、進化をどげ、より損害を与え、破壊的なものになっています。コンピュータシステムの維持管理において、セキュリティインシデントへの対応は、ITシステムの運用で必須且つ、重要な位置づけを占めています。
新しいタイプのセキュリティ関連のインシデントは、頻繁に発生し、リスクアセスメントに基づく予防活動だけでは、インシデントの数を減らすことができても、すべてのインシデントを防止できるわけではなく、インシデントの対応は、危険を迅速に検知し、損失と破壊を最小限に抑え、ITサービスを素早く復旧するために、日を追うごとに企業にとって重要度が増してきております。
国際規格 ISO 22300 「Security and resilience ? Vocabulary」は、ISO/TC 292(セキュリティ及びレジリエンス技術専門委員会)が管掌している「Security and resilience」に関する規格で用いられる用語を定義するための規格です。
その中で、インシデント レスポンスについて定義されています。
3.1.126
インシデント レスポンス(incident response)
差し迫った危険 (3.1.110)の原因を阻止し、および/または潜在的に不安定なイベント (3.1.96)または混乱 (3.1.75)の結果 (3.1.46)を軽減し、通常の状況に復旧するために講じる処置。
インシデント レスポンス(incident response)
差し迫った危険 (3.1.110)の原因を阻止し、および/または潜在的に不安定なイベント (3.1.96)または混乱 (3.1.75)の結果 (3.1.46)を軽減し、通常の状況に復旧するために講じる処置。
インシデント レスポンスは,緊急事態管理プロセスの一部ですが、企業や組織においては、一般的にセキュリティインシデントなどに対する復旧のための対応です。
つまり、システムの突然の停止、サイバー攻撃による不正アクセスや、情報漏えいなど、セキュリティを脅かしている事象であるインシデントが発生した場合に事後処理として、原因の調査、対応策の検討、サービス復旧などを適切に行うということが、インシデント レスポンスです。
(2) インシデント レスポンスの必要性
サイバー攻撃など、個人情報や、ビジネスにおける重要なデータを危険にさらすことが多く、セキュリティ インシデントが発生した場合には、迅速かつ効果的に対応することが重要です。
コンピュータ セキュリティにおいて、インシデント レスポンスの概念は広く受け入れられ、多くの企業や組織で実装されています。
インシデント レスポンスの対応能力を持つことの利点の1つは、適切なアクションが実行されるように、体系的に一貫したインシデント処理方法に従って、インシデントに対応することをサポートすることです。
インシデント レスポンスは、インシデントによって引き起こされる損失や情報の盗難、およびサービスの中断を最小限に抑えるのに役立ちます。
インシデント レスポンスのもう1つの利点は、インシデント処理中に取得した情報を使用して、将来起こりうるインシデントに対して、事前にある程度の備えと、システムの強靭性が改善できることです。
(3) インシデント レスポンス ライフサイクル
『NIST.SP.800-61r2』によると、インシデント レスポンスには、いくつかのフェーズがあり、大別すると4つのカテゴリーに分かれます。
準備、検知・分析、封じ込め、根絶、復旧、事後対応のフェーズによって、インシデント レスポンスのライフサイクルが形成されます。
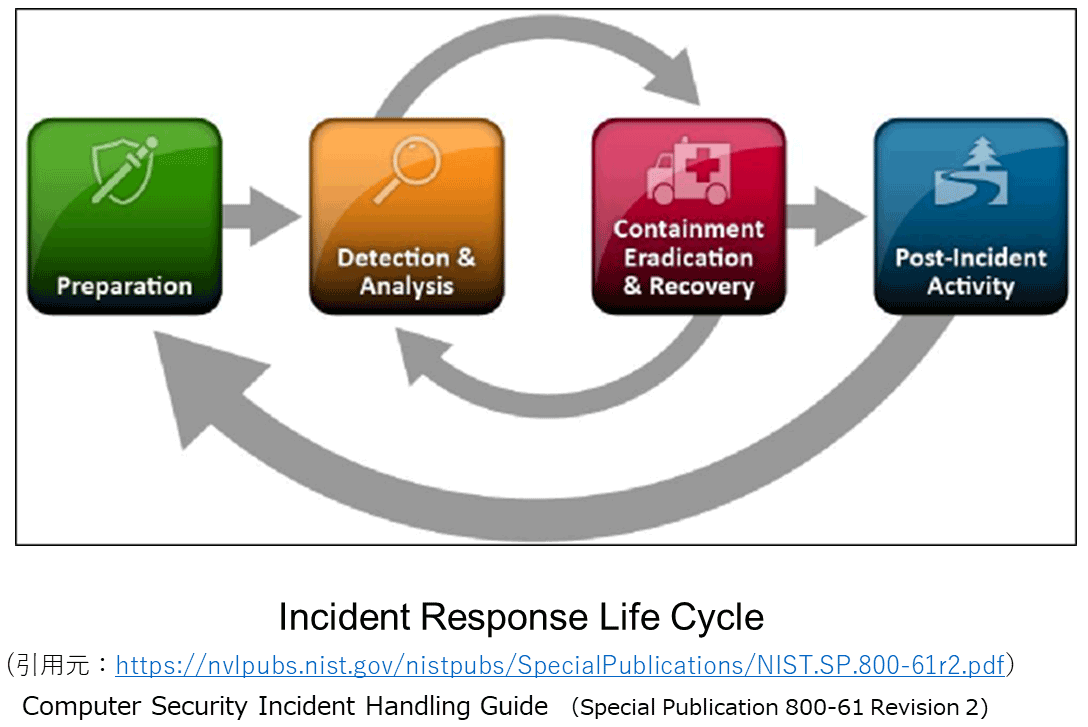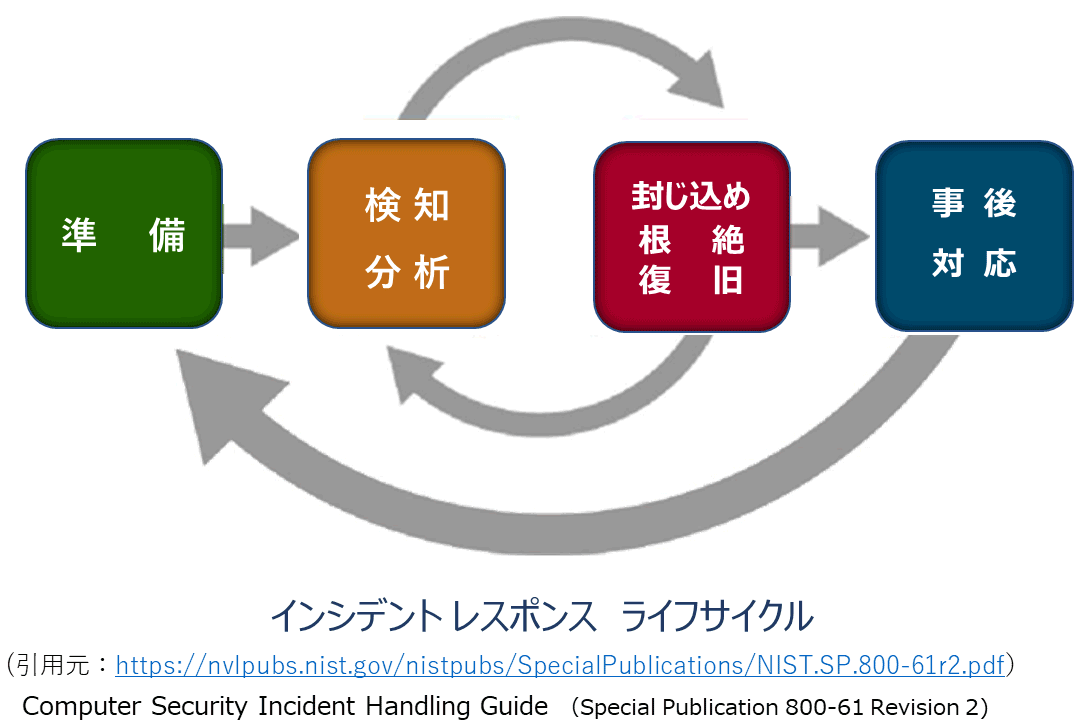
インシデント レスポンスのプロセスにはいくつかのフェーズがあります。
■ 準備(Preparation)
最初のフェーズでは、インシデント レスポンスを担当するチームを設立してトレーニングし、必要なツールとリソースを取得します。この準備中に、リスク評価の結果に基づいて、ツールとリソースを用いて一連の制御を実装することにより、発生するインシデントの数を可能な限り抑えようとします。
■ 検知・分析(Detection and Analysis)
事前対応が行われていても、残存リスクは残るため、インシデントが発生した場合に、迅速に把握するためには、セキュリティ違反などの検知と分析を行う仕組みが必要です。
■ 封じ込め、根絶、復旧(Containment, Eradication, and Recovery)
インシデントの重大度に合わせて、インシデントを封じ込め、最終的には復旧することで、インシデントの影響を軽減できます。
このフェーズでは、アクティビティが前のフェーズである検知と分析に戻ることがよくあります。たとえば、マルウェアインシデントを根絶する際に、追加のホストがマルウェアに感染していないかどうかを確認する場合などです。
■ 事後対応(Post-Incident Activity)
インシデントが適切に処理された後、インシデントの原因とコスト、および将来のインシデントを防ぐために組織が実行すべき手順を詳述したレポートを作成します。
(4) ログの重要性
インシデント レスポンスの各フェーズを実施するにあたり、多くの情報が必要になります。
そのため、様々な部門や組織のシステムからのログデータを如何に有効に活用できるかがポイントとなります。
インシデント レスポンスの各フェーズを理解することは、セキュリティ インシデントに対処できる適切なログ管理システムを構築する上で、有効な情報となります。
準 備(Preparation)
『NIST.SP.800-61r2』のインシデント レスポンスのライフサイクルの最初のカテゴリーは、Preparation(準備)です。
インシデント レスポンスを担当するチームを設立してトレーニングし、必要なツールとリソースを取得します。この準備中に、リスク評価の結果に基づいて、ツールとリソースを用いて一連の制御を実装することにより、発生するインシデントの数を可能な限り抑えようとします。

① インシデント処理の準備 (Preparing to Handle Incidents)
インシデントに対応するためには、常日頃より備えが必要です。
有効なログ管理システムを構築しておくとも、もちろんそれに該当しますが、『NIST.SP.800-61r2』の3.1.1 Preparing to Handle Incidentsには、もっと基礎的なインフラやソフトウェアが、インシデント対応には必要だとしています。
また、抜粋した以下のリストは、インシデントの対応時に有用なツールやリソースの例が示されています。
これらのリストは、組織のインシデント対応者がどのようなツールやリソースを必要としているかを議論するための出発点となることを意図しているようです。
たとえば、スマートフォンは、緊急事態のための連絡手段の1つであり、通信と調整を行うための一つの仕組みとなりますが、組織は、1つの対応のための仕組みが故障した場合に備えて、複数の独立した異なる連絡・調整ができる仕組みを持つべきだとしています。
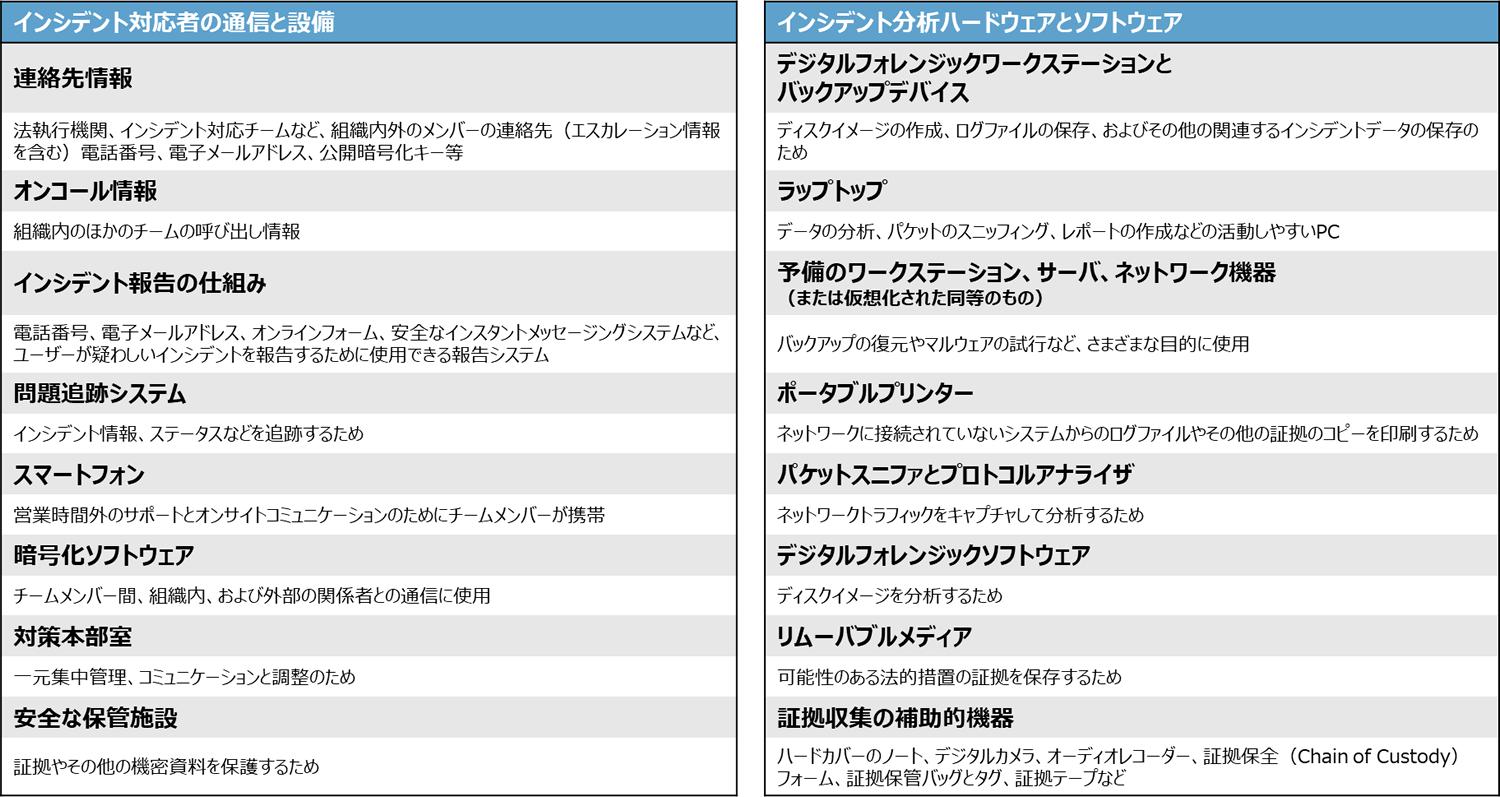
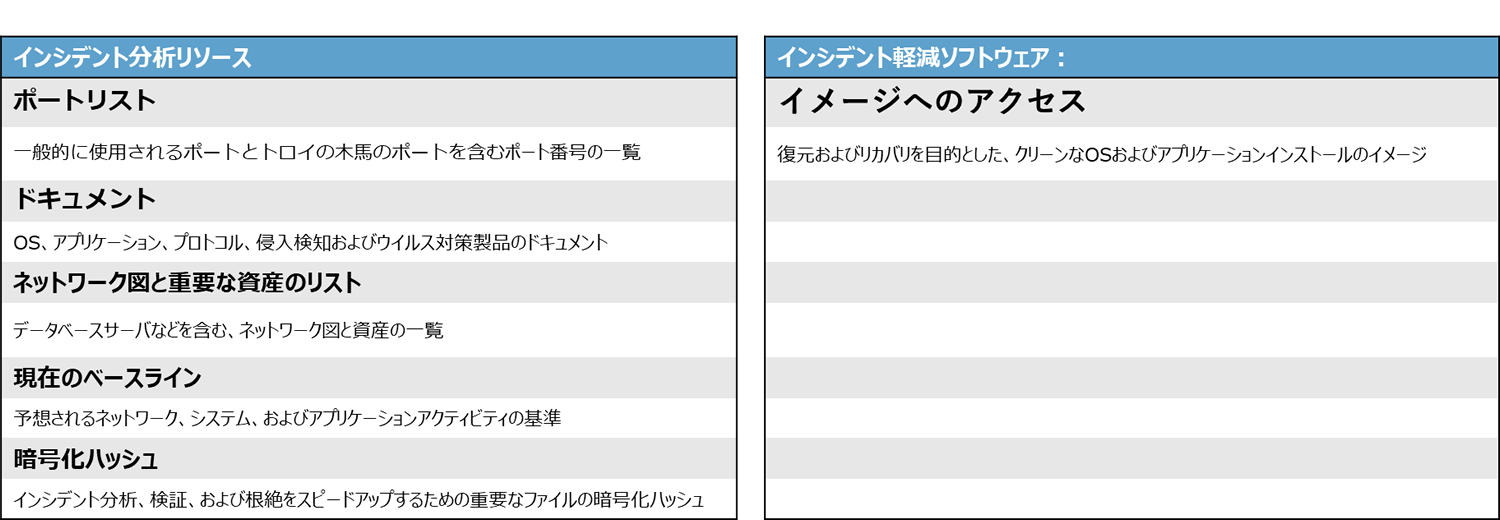
インシデント分析ハードウェアとソフトウェアの準備は、ログを解析する上で必要な機器やソフトウェアの洗い出しが必要なことがわかります。単に分析目的だけでなく、エビデンスを残すための道具を備えておくことがポイントになります。
そして、その分析の元となるリソースの確認も必要です。
このインシデント処理の準備に欠かせないのは、通信設備の中に、報告やエスカレーションも含め、物理的な物だけでなく連絡、連携ができるための仕組みです。
② インシデントの防止 (Preventing Incidents)
『NIST.SP.800-61r2』の3.1.2 Preventing Incidentsでは、可能な限りインシデントの数を最小限保つことは、企業や組織のビジネスプロセスを保護するためにとても重要で、セキュリティ管理が不十分な場合、インシデントの量が多くなり、インシデント対応チームの応答が遅くなる可能性があり、ビジネスへの悪影響が大きくなると解説されています。
インシデント対応チームは、組織が他の方法では認識していない問題を特定できる場合があり、チームは、ギャップを特定することにより、リスク評価とトレーニングで重要な役割を果たすことができるそうです。
以下は、その解説から、ネットワーク、システム、およびアプリケーションを保護するための主な推奨プラクティスのいくつかの概要を抜粋しました。
■ リスク評価
システムおよびアプリケーションの定期的なリスクアセスメントでは、脅威と脆弱性の組み合わせによってどのようなリスクがもたらされるかを、判断する必要があります。これには、組織特有の脅威を含み、適用が可能な脅威も含まれます。洗い出された各リスクには優先順位をつけ、リスクの全体的なレベルが妥当なものになるまで、リスクを軽減、転嫁、または受容することができます。リスクアセスメントを定期的に実施することのもう一つの利点は、重要なリソースが特定されることで、それらのリソースに対する監視および対応活動を重視して行うことできることです。
■ ホストセキュリティ
すべてのホストは、標準構成を使用して適切に強化する必要があります。各ホストに適切なパッチを適用することに加えて、許可されたタスクを実行するために必要なユーザーにのみ特権を付与します。ホストは監査を有効にし、重要なセキュリティ関連のイベントをログに記録する必要があります。ホストとその構成のセキュリティは継続的に監視する必要があります。
■ ネットワークセキュリティ
ネットワークの境界は、明示的に許可されていないすべてのアクティビティを拒否するように構成する必要があります。これには、仮想プライベートネットワーク(VPN)や他の組織への専用線の接続など、すべての接続ポイントの保護が含まれます。
■ マルウェアの防止
マルウェアを検出して阻止するソフトウェアは、組織全体に展開する必要があります。マルウェア保護は、ホストレベル(サーバおよびワークステーションオペレーティングシステムなど)、アプリケーションサーバレベル(電子メールサーバ、Webプロキシなど)、およびアプリケーションクライアントレベル(電子メールクライアント、インスタントメッセージングクライアントなど)で展開する必要があります。
■ ユーザの認識とトレーニング
ユーザは、ネットワーク、システム、およびアプリケーションの適切な使用に関するポリシーと手順を知っておく必要があります。以前のインシデントから学んだ該当する教訓もユーザーと共有して、ユーザーが自分の行動が組織にどのように影響するかを確認できるようにする必要があります。インシデントに関するユーザーの認識を向上させると、インシデントの頻度を減らすことができます。ITスタッフは、組織のセキュリティ標準に従ってネットワーク、システム、およびアプリケーションを維持できるようにトレーニングする必要があります。
まず、リスク評価は、インシデントというリスクの管理を行う上で、最も重視すべきで、定期的にリスクアセスメントを行い、優先順位を付け、監視すべき重要なリソースを特定するところがポイントです。これは、ログ管理をする上でも欠かせない点で、リスクすべてを防止できるとは思わず、脅威と脆弱性を評価した上で、リスクの内容によっては、軽減や受容も受け入れることが必要になります。
そして、インシデント発生の防止には、強靭なセキュリティを守る仕組みは必須で そのためにはログ管理と連動した、様々なセキュリティツールの選定と導入も見直しが必要になるかもしれません。
そして、インシデントの防止で忘れてならないのは、セキュリティポリシーを設定するだけでなく、ユーザに認知してそれに則した行動をしてもらえるよう、トレーニングなどを通じて、ポリシーだけでなく、教訓も含め学習してもらうことです。これは、ログ管理システムや、セキュリティツールなど、どんなに有効な仕組みを構築しても、最終的には人がコントロールすべきものなので、ツール任せで防ぎきれるわけではないということです。
検知・分析(Detection and Analysis)
『NIST.SP.800-61r2』のインシデント レスポンスのライフサイクルの2番目のカテゴリーは、Detection and Analysis(検知・分析)です。
様々な種類のシステムのログなどをもとに、インシデントを可能な限り素早く発見して、状況や影響度、原因、対応策などが分析できる仕組みが必要です。

① 攻撃ベクトル (Attack Vectors)
『NIST.SP.800-61r2』の3.2.1 Attack Vectorsのセクションには、インシデントはいろいろな形で発生する可能性があるため、すべてのインシデントを処理するための手順を作成することは不可能であり、あらゆるインシデントに対応できるように準備をする必要はありますが、まずは一般的な攻撃ベクトルを使用するインシデントを処理する準備に重点を置く必要があると記載しています。但し、インシデントの種類が異なれば、対応戦略も違ってきます。
以下にリストされている攻撃ベクトルは、単に攻撃の一般的な方法をリストしており、より具体的な処理手順を定義するためのベースとして使用できるとのことです。
■ 外部/リムーバブルメディア
リムーバブルメディアまたは周辺機器から実行される攻撃。
たとえば、感染したUSBフラッシュドライブからシステムに悪意のあるコードが拡散します。
■ アトリション
システム、ネットワーク、またはサービスを侵害、劣化、または破壊するためにブルートフォース方式を使用する攻撃。
たとえば、サービスまたはアプリケーションへアクセスを邪魔するDDoS攻撃、パスワード、CAPTCHAS、またはデジタル署名の認証方式に対するブルートフォース攻撃など。
■ Web
WebサイトまたはWebベースのアプリケーションから実行される攻撃。
たとえば、資格情報を盗むために使用されるクロスサイトスクリプティング攻撃や、ブラウザの脆弱性を悪用してマルウェアをインストールするサイトへのリダイレクトです。
■ 電子メール
電子メールメッセージまたは添付ファイルを介して実行される攻撃。
たとえば、添付文書を装ったコードや、電子メールメッセージの本文にある悪意のあるWebサイトへのリンクを悪用します。
■ なりすまし
なりすまし、中間者攻撃、不正なワイヤレスアクセスポイント、SQLインジェクション攻撃など、良性のものを悪意のあるものに置き換える攻撃には、すべてなりすましが含まれます。
■ 不適切な使用
上記のカテゴリを除く、許可されたユーザーによる組織の利用規定の違反に起因するインシデント。
たとえば、ユーザーがファイル共有ソフトウェアをインストールすると、機密データが失われるケースや、ユーザがシステム上で違法な不正を行った場合などです。
■ 機器の紛失または盗難
ラップトップ、スマートフォン、認証トークンなど、組織が使用するコンピューティングデバイスまたはメディアの紛失または盗難。
■ その他
他のどのカテゴリーにも当てはまらない攻撃。
攻撃ベクトル (Attack Vectors)は、サイバーセキュリティの分野では、攻撃ベクトルは、ハッカーがターゲットシステムにアクセスまたは侵入するために使用する方法または経路のことです。
様々な攻撃ベクトルがあり、インシデント対応者にとってはリストにあるような一般的な攻撃手法や経路を整理しておくことが必要です。ここでも、当然ながらその攻撃方法や、経路を見極めるためにログが要ととなってきます。
② インシデントの兆候 (Signs of an Incident )
『NIST.SP.800-61r2』の3.2.2 Signs of an Incidentのセクションでは、多くの組織にとって、インシデント対応プロセスの最も難しい部分は、発生する可能性のあるインシデントを正確に検知して評価することと解説しています。
インシデントが発生したかどうか、発生した場合は、問題の種類、範囲、規模を判断しますが、これを非常に困難にしているのは、次の3つの要因の組み合わせとのことです。
● インシデントは、様々なレベルの精度で、いろりろな方法により検知できます。自動検知機能には、ネットワークベースおよびホストベースのIDPS(侵入検知防御システム)、ウイルス対策ソフトウェア、およびログ管理システム等が含まれます。インシデントは、ユーザから報告された問題など、手動で検出する場合もあります。一部のインシデントには、簡単に検知できる明白な兆候がありますが、他のインシデントはほとんど検知できません。
● インシデントの潜在的な兆候の量は、一般的に多くなります。
● インシデント関連データを適切かつ効率的に分析するには、深い専門的な技術知識と豊富な経験が必要です。
インシデントの兆候は、前兆と兆候の2つのカテゴリのいずれかに分類され、前兆は、インシデントが将来発生する可能性の兆候で、兆候は、インシデントが発生した可能性があるか、あるいは現在発生していることのあらわれと定義されています。
ほとんどの攻撃には、ターゲット側からの観点では、識別可能または検出可能な前兆がなく、もし前兆が見つかった場合、組織は、ターゲットを攻撃から保護するためにセキュリティ体制を変更することにより、インシデントを防止する機会を得る可能性があり、少なくとも、ターゲットが関与するアクティビティをより綿密に監視できるとのことです。
前兆は次ような例が記載されています。
● 脆弱性スキャナーの使用状況を示すWebサーバーのログエントリ
● 組織のメールサーバーの脆弱性を標的とする新しいエクスプロイトの発表
● グループが組織を攻撃することを示すグループからの脅威
前兆は比較的まれですが、兆候はとても一般的です。それらを網羅的にリストするには多すぎるタイプの兆候が存在しますが、いくつかの例を以下にリストします。
● データベースサーバに対してバッファオーバーフローが発生すると、ネットワーク侵入検知センサーが警告を発します。
● ウイルス対策ソフトウェアは、ホストがマルウェアに感染していることを検出すると警告を発します。
● システム管理者には、異常な文字を含むファイル名が表示されます。
● ホストは、監査に必要ば構成の変更をログに記録します。
● アプリケーションは、見慣れないリモートシステムからの複数の失敗したログイン試行をログに記録します。
● 電子メール管理者は、疑わしいコンテンツを含む大量に送られてくる電子メールを確認します。
● ネットワーク管理者は、通常のネットワークトラフィックフローからの異常な逸脱に気づきます。
このセクションのSigns of an Incidentでは、signsを”兆候”と解釈しましたが、他にprecursors、indicatorsという単語が使用されています。
precursorsは、”前兆”と訳し、indicatorsは、直訳では”指標”となってしまうのですが、文章の意図を汲むとあえて、indicatorsも”兆候”という言葉で表現させていただきました。
前兆と兆候も似た言葉ですが、signsも日本語の訳では”兆候”もあり、その違いを一言で表すのは難しいです。ご興味のある方は、原文の 『NIST.SP.800-61r2』の3.2.2 Signs of an Incidentのセクションをご確認いただくことをお勧めいたします。
③ 前兆と兆候の情報源 (Sources of Precursors and Indicators)
『NIST.SP.800-61r2』の3.2.3 Sources of Precursors and Indicatorsで、前兆と兆候は、多くの異なるソースを使用して識別され、最も一般的なのは、コンピューターセキュリティソフトウェアのアラート、ログ、公開されている情報、および人だとしています。
以下に、その各カテゴリの前兆と兆候の一般的なソースを抜粋します。

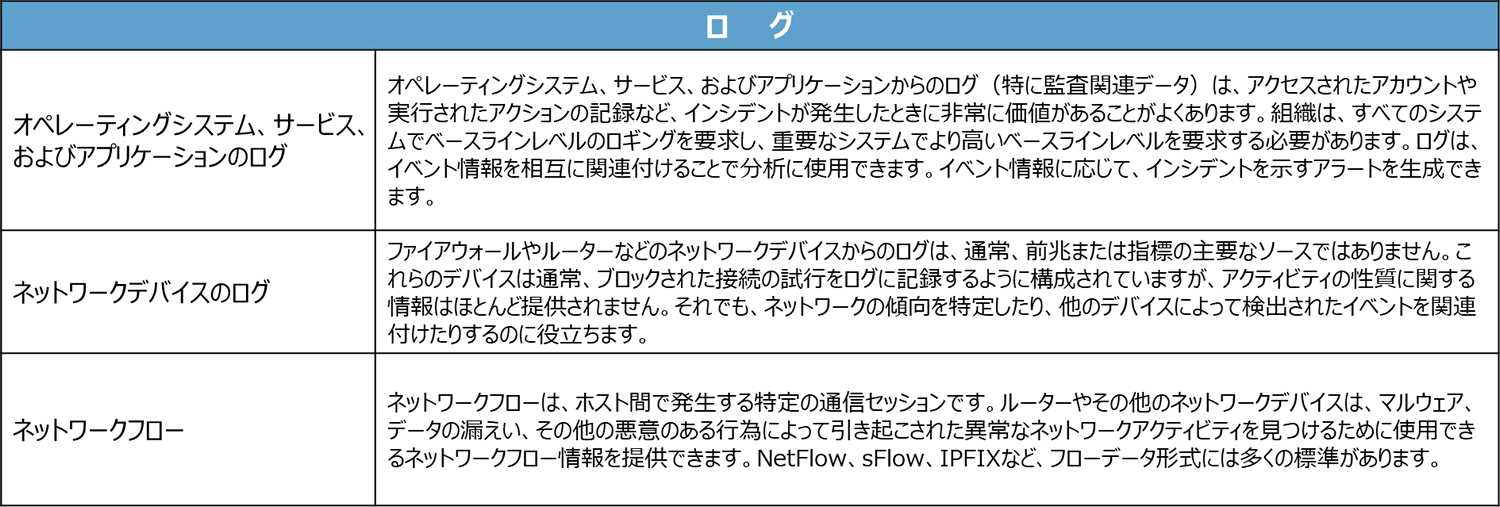

アラートを出す仕組みの多くは、セキュリティツールがメインですが、その中でもSIEMは、ログデータをもとにリアルタイムに近い形でログを分析してアラートを上げることができます。
ログのカテゴリにあるOSのログ、アプリケーションのログ、ネットワークのログはそれぞれのシステムでアラートメッセージを送信する設定を行います。こうした、設定だけでは期待するアラートがうまく取得できな場合や、分かり易いメッセージに変更したい場合など、ログ管理システム側の機能を利用して補完することが必要となります。
インシデントの情報源として、その障害が起こったシステム側の情報だけでなく、脆弱性情報データベースの利用や、関連しそうな社内外すべての人からの情報もうまく活用することがポイントとなります。
④ インシデント分析 (Incident Analysis)
『NIST.SP.800-61r2』の3.2.4 Incident Analysisには、すべての前兆または兆候が正確であることが保証されていれば、インシデントの検知と分析は簡単ですが、残念ながらそうではなく、たとえば、サーバが利用できないという苦情など、ユーザが提供する兆候は正しくないことがよくあり、侵入検知システムは、誤検知を生成する可能性があるとしています。こうしたことが、インシデントの検出と分析を非常に困難にしており、理想的には、各兆候を評価して、それが正当であるかどうかを判断する必要があるのですが、兆候の総数は膨大になる可能性があり、すべての兆候から発生した実際のセキュリティインシデントを見つけることは、困難な作業になる可能性があるとしています。
兆候が正確であっても、必ずしもインシデントが発生したことを意味するわけではなく、サーバのクラッシュや、重要なファイルの変更などの一部の兆候は、人為的ミスなど、セキュリティインシデント以外の理由で発生する可能性があります。ただし、兆候の発生について考えると、インシデントが発生している可能性があると疑って、それに応じて行動することは合理的だとしています。
特定のイベントが実際にインシデントであるかどうかを判断する決定を下すために、他の技術および情報セキュリティ担当者と協力する必要があり、多くの場合、状況は、セキュリティに関連しているかどうかに関係なく、同じ方法で処理する必要があるようです。たとえば、一定時間ごとにインターネット接続ができなくなり、誰も原因を知らない場合、明らかに改ざんされたWebページなど、一部のインシデントは簡単に検出できますが、多くのインシデントはそのような明らかな症状とは関係がありません。
1つのシステム構成ファイルの1つの変更などの小さな兆候が、インシデントが発生したことを示す唯一の兆候である可能性があり、インシデント処理では、検知が最も難しいタスクになる場合があります。インシデント対応者は、あいまいで矛盾した不完全な症状を分析して、何が起こったのかを判断する責任があり、より簡単で最善の救済策は、前兆と兆候を効果的かつ効率的に分析し、適切な行動を取ることができる経験豊富で熟練したスタッフのチームを構築することのようです。それは逆に、十分な訓練を受けた有能なスタッフがいなければ、インシデントの検出と分析は非効率的に行われ、コストのかかるミスが発生する恐れがあります。
インシデント対応チームは、事前に定義されたプロセスに従い、実行された各ステップを文書化して、各インシデントを分析および検証するために迅速に作業する必要があり、チームがインシデントが発生したと確信した場合、チームは初期分析を迅速に実行して、影響を受けるネットワーク、システム、またはアプリケーションなどのインシデントの範囲を決定する必要があります。
誰が、または何がインシデントを引き起こしたか、インシデントがどのように発生しているか、たとえば、どのツールまたは攻撃方法が使用されているか、どの脆弱性が悪用されているかなど、最初の分析では、インシデントの封じ込めやインシデントの影響のより詳細な分析など、チームが後続のアクティビティに優先順位を付けるのに十分な情報を提供する必要があります。
初期分析と検証の実行はかなり難しいので、以下は、インシデント分析をより簡単かつ効果的にするための推奨事項の抜粋です。
■ プロファイルネットワークとシステム
プロファイリングとは、予想されるアクティビティの特性を測定して、アクティビティへの変更をより簡単に識別できるようにすることです。プロファイリングの例としては、ホスト上でファイル整合性チェックソフトウェアを実行して重要なファイルのチェックサムを導き出し、ネットワーク帯域幅の使用状況を監視して、さまざまな日時の平均およびピーク使用量レベルを判断します。実際には、プロファイリング手法を使用してインシデントを正確に検出することは難しいため、いくつかの検出および分析手法の1つとしてプロファイリングを使用する必要があります。
■ 通常の動作の理解
インシデント対応チームのメンバーは、ネットワーク、システム、およびアプリケーションを調査して、異常な動作をより簡単に認識できるように、正常な動作が何であるかを理解する必要があります。インシデント対応者は、環境全体のすべての動作に関する包括的な知識を持っているわけではないですが、どういった専門知識がそのギャップを埋めてくれるのかを知っている必要があります。この知識を得る1つの方法は、ログエントリとセキュリティアラートを確認することです。ログを適切なサイズに圧縮するためにフィルタリングが使用されていない場合、ログの分析を面倒にする場合があります。対応者がログとアラートに精通するにつれて、対応者は理解しづらいエントリに集中でき、調査するためにより重要になります。頻繁にログについてのレビューを実施することで知識を最新に保つ必要があり、分析者は時間の経過に伴う傾向や変化に気付くことができるはずです。
■ ログ保持ポリシーの作成
インシデントに関する情報は、ファイアウォール、IDPS、アプリケーションログなどのいくつかの場所に記録される場合があります。古いログエントリは偵察活動または同様の攻撃の以前のインスタンスを示す可能性があるため、ログデータを維持する期間を指定するログ保持ポリシーを作成して実装すると、分析に非常に役立つ場合があります。ログを保持するもう1つの理由は、インシデントが数日、数週間、さらには数か月後まで発見されない可能性があることです。ログデータを維持する時間の長さは、組織のデータ保持ポリシーやデータの量など、いくつかの要因によって異なります。
■ イベントの相関を実施
インシデントのエビデンスは、それぞれが異なるタイプのデータを含む複数のログにキャプチャされる場合があります。ファイアウォールログには使用された送信元IPアドレスが含まれる場合がありますが、アプリケーションログにはユーザー名が含まれる場合があります。ネットワークIDPSは、特定のホストに対して攻撃が開始されたことを検出する場合がありますが、攻撃が成功したかどうかはわかりません。アナリストは、その情報を判別するためにホストのログを調べる必要がある場合があります。複数のインジケーターソース間でイベントを関連付けることは、特定のインシデントが発生したかどうかを検証する上で非常に重要です。
■ すべてのホストクロックの同期を維持
ネットワークタイムプロトコル(NTP)などのプロトコルは、ホスト間でクロックを同期します。イベントを報告するデバイスのクロック設定に一貫性がない場合、イベントの相関はより複雑になります。エビデンスの観点から、ログに一貫したタイムスタンプを設定することが必要です。
■ 情報の知識ベースを維持と使用
ナレッジベースには、インシデント分析中に対応者がすばやく参照するために必要な情報を含める必要があります。複雑な構造の知識ベースを構築することは可能かもしれないですが、シンプルなデータベースが効果的です。テキストドキュメント、スプレッドシート、および比較的単純なデータベースは、チームメンバー間でデータを共有するための効果的で柔軟かつ検索可能な仕組みを提供します。ナレッジベースには、IDPSアラート、オペレーティングシステムのログエントリ、アプリケーションのエラーコードなど、前兆と兆候の重要性と有効性の説明など、さまざまな情報も含まれている必要があります。
■ リサーチ用にインターネット検索エンジンの使用
インターネット検索エンジンは、分析者が異常な活動に関する情報を見つけるのに役立ちます。たとえば、分析者は、TCPポート22912をターゲットとする異常な接続試行を確認する場合に、「TCP」、「ポート」、および「22912」という用語で検索を実行すると、同様のアクティビティのログまたは説明や、ポート番号の重要性を含む内容が見つかる場合があります。検索実行のリスクを最小限に抑えるために、調査には別々のワークステーションを使用する必要があります。
■ パケットスニファを実行して追加データを収集
兆候は、対応者が何が起こっているのかを理解するのに十分な情報がない場合があります。インシデントがネットワークを介して発生している場合、必要なデータを収集する最も速い方法は、パケットスニファにネットワークトラフィックをキャプチャさせることです。指定された基準に一致するトラフィックを記録するようにスニファーの構成を設定するとき、データの量を管理しやすくし、他の情報の不注意によるキャプチャを最小限に抑える必要があります。プライバシー上の懸念から、一部の組織では、パケットスニファを使用する前に、インシデント対応者が許可をもらう必要がある場合があります。
■ データのフィルタリング
すべての兆候を確認して分析するのに十分な時間はとれないため、少なくとも、最も疑わしい活動を調査する必要があります。効果的な戦略の1つは、重要ではない傾向のある兆候のカテゴリを除外することです。別のフィルタリング戦略は、最も重要な兆候のカテゴリのみを表示することです。ただし、このアプローチには、新しい悪意のあるアクティビティが、選択した兆候のカテゴリのいずれにも分類されていない可能性があるため、かなりのリスクが伴います。
■ 他人からの援助を要求
場合によっては、チームがインシデントの完全な原因と性質を特定できないことがあります。チームがインシデントを封じ込めて根絶するのに十分な情報が不足している場合は、情報セキュリティスタッフなどの内部リソース、および専門知識を持つ外部リソースに相談する必要があります。各インシデントの原因を正確に特定して、インシデントを完全に封じ込め、悪用された脆弱性を軽減して同様のインシデントの発生を防ぐことが重要です。
まず、プロファイリングは重要です。アクティビティへの変更を簡単に識別できる仕組みは、対象によって異なるため、ツールを使用したとしても検出や分析を意図して、個別に適切な方法を適用する必要があります。
そしてそれに関連する通常の動作の理解には、ログやアラートが専門知識とのギャップを埋める大事な役割を担います。ログについて頻繁にレビューを実施できるよう、ログ管理システムに定期的なレポーティングなどを組み込んでおくことが、知識を最新に保ち、その結果、分析の精度や速度を上げ効率化できることになります。
また、的確な分析を実施できるようにするためには、必要なログが保持されていなければなりません。そのログ保持期間のポリシーに沿って、ログ管理システムが構築されます。
インシデントの分析には、イベント相関の実施が必要になることが多いです。各システムのログを関連付けて分析するためには、ログのフォーマットを統一して、複数種類のログを一度に検索したり、集計したりできる仕組みが、ログ管理システムに備わってくことが必要になります。
その複数ログの相関分析するためには、当然各システムから収集されたログのタイムスタンプの時刻が違っていては正確に処理できません。各種のログを一貫して正確なタイムスタンプにすることは、ログ管理システム構築に重要なポイントとなります。
インシデントの分析においては、ログ管理ツールの分析機能の使用が役立ちます。複数ログの横断検索など、どんな分析をどこまでできるかが、ツール選択のカギになります。
⑤ インシデント ドキュメント (Incident Documentation)
『NIST.SP.800-61r2』の3.2.5 Incident Documentationで、インシデント対応チームは、インシデントが発生したと疑われると、インシデントに関するすべての事実の記録を直ちに開始する必要があるとしています。
システムが残すログは、このための効果的で単純な媒体ですが、
オーディオレコーダー、デジタルカメラもこの目的を果たすことができ、システムイベント、会話、およびファイル内で操作された変更を文書化すると、問題の処理がより効率的に体系的で、エラーが発生しにくくなるとのことです。
また、インシデントが検知されてから最終的な解決までのすべての手順を文書化し、タイムスタンプを付ける必要があり、インシデントに関するすべての文書には、インシデント対応者が日付を記入し、署名する必要があるとしています。この種の情報は、法的訴追が行われる場合に法廷で証拠として使用することもでき、可能な場合は常に、対応者は少なくとも2人のチームで作業し、1人はイベントをログとして記録し、もう1人は技術的なタスクを実行するとよいそうです。
インシデント対応チームは、他の関連情報とともに、インシデントのステータスに関する記録を継続する必要がありますが、インシデントがタイムリーに処理および解決されるようになるため、アプリケーションまたは問題追跡システムなどのデータベースを使用することが有効であり、問題追跡システムには、次の情報が含まれている必要があるそうです。
● インシデントの現在のステータス(新規、進行中、調査のために転送、解決など)
● インシデントの概要
● インシデントに関連する兆候
● このインシデントに関連する他のインシデント
● このインシデントに対してすべてのインシデント対応者が実行するアクション
● 該当する場合、証拠保全(Chain of Custody)
● インシデントに関連する影響評価
● 他の関係者(システム所有者、システム管理者など)の連絡先情報
● インシデント調査中に収集されたエビデンスのリスト
● インシデント対応者からのコメント
● 実行する次の手順(たとえば、ホストの再構築、アプリケーションのアップグレード)
インシデントの対応についての、ステータス等のドキュメントをデジタルデータ化すると、チームや関係者の間で共有し易くなりますが、インシデントデータには、機密情報が含まれていることが多いため、インシデントデータを保護し、悪用された脆弱性、最近のセキュリティ違反、不適切なアクションを実行した可能性のあるユーザに関するデータなど、アクセスを制限する必要があるようです。たとえば、許可された担当者のみが、インシデントデータベースにアクセスできるようにし、電子メールなどを使用したインシデントの通信およびドキュメントは、許可された担当者のみが読み取ることができるように、暗号化またはその他の方法で保護する必要があります。
⑥ インシデントの優先順位付け (Incident Prioritization)
『NIST.SP.800-61r2』の3.2.6 Incident Prioritizationでは、インシデントの処理に優先順位を付けることは、インシデント処理プロセスでおそらく最も重要な決定ポイントだとしています。リソースの制限の結果として、インシデントは先着順で処理されるべきではなく、代わりに、次のような関連する要因に基づいて処理に優先順位を付ける必要があるとのことです。
■ インシデントの機能的影響
ITシステムを標的とするインシデントは、通常、それらのシステムが提供するビジネス機能に影響を与え、その結果、それらのシステムのユーザに何らかの悪影響を及ぼします。インシデント対応者は、インシデントが影響を受けるシステムの既存の機能にどのように影響するかを検討する必要があります。インシデント対応者は、インシデントの現在の機能的影響だけでなく、インシデントがすぐに封じ込められない場合は、インシデントの将来の機能的影響の可能性も考慮する必要があります。
■ インシデントの情報への影響
インシデントは、組織の情報の機密性、完全性、および可用性に影響を与える可能性があります。たとえば、悪意のあるエージェントが機密情報を盗み出す可能性があり、インシデント対応者は、この情報の漏えいが組織の全体的な使命にどのように影響するかを検討する必要があります。機密情報の漏洩につながるインシデントは、パートナー組織に関連するデータがある場合、他の組織にも影響を与える可能性があります。
■ インシデントからの復旧の可能性
インシデントの規模とそれが影響するリソースの種類によって、そのインシデントからの回復に費やさなければならない時間とリソースの量が決まります。機密情報が漏えいした場合など、場合によっては、インシデントから復旧することができないこともあります。また、限られたリソースを長期にわたるインシデント対応のサイクルに費やすことは、将来同様のインシデントが発生しないようにするための努力でない限り、意味がありません。他のケースでは、インシデントを処理するために、組織が利用可能なリソースよりもはるかに多くのリソースを必要とする場合があります。インシデント対応者は、インシデントから実際に復旧するために必要な労力を考慮し、復旧作業が生み出す価値やインシデント処理に関連する要件と慎重に比較検討する必要があります。
システムへの機能的な影響と組織の情報への影響を組み合わせることで、インシデントのビジネスへの影響が決まるそうです。たとえば、パブリックWebサーバに対するDDoS攻撃により、サーバにアクセスしようとするユーザの機能が一時的に低下する可能性が想定され、一方、パブリックWebサーバへの不正なルートレベルのアクセスは、個人を特定できる個人情報の漏えいにつながる可能性があり、組織の評判に長期的な影響を与える可能性があると考えられるからです。
インシデントからの復旧の可能性をもとに、インシデントを処理するときに取る対応が決定され、機能への影響が大きく、復旧するための労力が少ないインシデントは、チームからの即時アクションが可能なインシデントは、理想的ですが、一部のインシデントにはスムーズな復旧パスがなく、より戦略的なレベルの対応のために待ち行列に入れる必要がある場合があるとのことです。
たとえば、攻撃者がギガバイト単位の機密データを流出させ、それを公開するようなインシデントは、データが既に公開されているため、容易には復旧できません。このような場合、チームはデータ漏えいのインシデントの処理責任の一部を、より戦略的なレベルのチームに移すことで、このチームは、将来の侵害を防止するための戦略を策定し、データが流出した個人または組織に警告を与えるためなどに時間を有効に使えます。
対応チームは、インシデントによって引き起こされるビジネス上の影響の見積もりと、インシデントからの回復に必要な労力の見積もりに基づいて、各インシデントへの対応の優先順位を決定する必要があります。
組織は、状況を認識しているため、自身のインシデントの影響を最もよく定量化できます。
インシデントの評価は、限られたリソースに優先順位を付けるのに役立つとのことなので、以下は、組織が独自のインシデントを評価するために使用する可能性のある機能的影響カテゴリの例を抜粋しました。

インシデント中に発生した情報侵害の程度を説明するために考えられる情報影響カテゴリの例を抜粋しました。この表では、「なし」の値を除いて、カテゴリーは相互に排他的ではなく、組織は複数を選択できるそうです。

インシデントからの復旧に必要なリソースのレベルと、タイプを反映する回復可能性の取り組みカテゴリの例を抜粋しました。
インシデントの優先順位付けを、こうした機能的影響、情報影響、回復可能性の3つの観点から整理すると、確かに基準が明確になり有効な手段だと思われますので、各企業や組織はこうした例を参考に、独自の判断基準で優先順位付けを行っておくべきです。
そうすれば、トラブブルが重なった場合など、比較的冷静に何を優先すべきか誰にでも判断でき、最適な対処に役立ちます。その際の影響度や個人情報の有無などの情報を得るためにはログ管理が重要になってきます。

⑦ インシデント通知 (Incident Notification)
『NIST.SP.800-61r2』の3.2.7 Incident Notificationでは、インシデントが分析され、優先順位が付けられると、インシデント対応チームは適切な個人に通知して、関与の必要があるすべての人がそれぞれの役割を果たすようにするとあります。
インシデント対応ポリシーには、たとえば、初期通知、定期的なステータスの更新など、少なくとも、何を誰にいつ報告する必要があるかのインシデントの報告に関する規定を含めます。
正確なレポート要件は組織によって異なりますが、通常通知される関係者は次のとおりとのことです。(抜粋)
● CIO
● 情報セキュリティ責任者
● 地域情報セキュリティ責任者(該当する場合)
● 組織内の他のインシデント対応チーム
● 外部インシデント対応チーム(該当する場合)
● システム所有者
● 人材(メールによるハラスメントなど、従業員が関与する場合)
● 広報(宣伝を生み出す可能性のあるインシデントの場合)
● 法務部門(法的な影響が生じる可能性のあるインシデントの場合)
● 法執行機関(該当する場合)
インシデント処理中に、チームは、場合によっては組織全体であっても、特定の関係者にステータスの更新を提供する必要がある場合があり、チームは、たとえば、対面、紙などネットワーク帯域を使用しない方法を含むいくつかの通信方法を計画および準備し、特定のインシデントに適した方法を選択する必要があるとのことです。
可能な通信方法の抜粋は、次のとおりです。
● Eメール
● Webサイト(内部、外部、またはポータル)
● 電話
● 対面(例、毎日の報告)
● ボイスメールボックスグリーティング(たとえば、インシデント更新用に別のボイスメールボックスを設定し、現在のインシデントステータスを反映するようにグリーティングメッセージを更新します。ヘルプデスクのボイスメールグリーティングを使用します)
● 紙(例:掲示板やドアに通知を掲載する、すべての入り口で通知を配布する)
インシデントの通知は、企業や組織の規模で、どこまで、どういったルートで行うかが異なってきますが、そのインシデントの種類によって、適切な手段と方法をルール化することが必要です。
このフェーズで取り上げられている通知は、ログ管理等で自動的にアラート通知される対応担当者とは別に、インシデントが分析され、優先順位が付けられた後の関係者への通知のことなので、インシデント対応中の状況報告も含みます。この対応に不備があると、復旧が完了していないのに、業務を再開してしまうトラブルや、復旧の目途が分からず余計な不安を拡大させることなどを避けるためにも重要なポイントになります。
ログ管理システムの構築による通知の自動化支援とはまったく違った視点で、かなり人のコミュニケーション能力にも依存し、関連する多くの人がそれぞれの役割を果たす大切なフェーズであるようです。
封じ込め、根絶、復旧
(Containment, Eradication, and Recovery)
『NIST.SP.800-61r2』の第3番目のカテゴリーは、Containment, Eradication, and Recovery(封じ込め、根絶、復旧)です。
インシデント対応者は、ログを最大限活用して、インシデントの封じ込め、根絶、復旧のための活動を行います。ライフサイクル内では、適宜前のカテゴリーである検知・分析に戻って、対処を重ねていく場合も多いです。

① 封じ込め戦略の選択 (Choosing a Containment Strategy)
『NIST.SP.800-61r2』の3.3.1 Choosing a Containment Strategyでは、インシデントがリソースを逼迫させたり、被害を増大させたりする前に、ほとんどのインシデントは封じ込めが必要であるため、各インシデントを処理する初期の段階で対応すべき重要な事項だとしています。
封じ込めができると、適切な処置を行うための戦略を作成するための時間を創出できます。封じ込めの重要な部分は、たとえば、システムをシャットダウンし、ネットワークから切断し、特定の機能を無効にするなどの意思決定ですが、インシデントを封じ込めるための事前に決定された戦略と手順がある場合、そのような決定ははるかに簡単になるため、組織は、インシデントに対処する際の許容可能なリスクを定義し、それに応じて戦略を策定する必要があるとのことです。
封じ込め戦略は、インシデントの種類によって異なります。たとえば、電子メールを介したマルウェア感染を封じ込めるための戦略は、ネットワークベースのDDoS攻撃の戦略とはまったく異なります。組織は、意思決定を容易にするために明確に文書化された基準を使用して、主要なインシデントタイプごとに個別の封じ込め戦略を作成する必要があり、適切な戦略を決定するための基準を次に抜粋しました。
● リソースへの潜在的な損傷と盗難
● エビデンス保存の必要性
● サービスの可用性(ネットワーク接続、外部の関係者に提供されるサービスなど)
● 戦略の実施に必要な時間とリソース
● 戦略の有効性(例、部分的封じ込め、完全封じ込め)
● ソリューションの期間(たとえば、4時間で削除される緊急の回避策、2週間で削除される一時的な回避策、永続的な解決策)
場合によっては、一部の組織は攻撃者をサンドボックスに封じ込めて、攻撃者のアクティビティを監視し、通常は追加のエビデンスを収集できるようする方法がありますが、インシデント対応チームは、この戦略を法務部門と話し合い、実行可能かどうかを判断する必要があります。監視する方法として、サンドボックス化以外の攻撃者のアクティビティは使用してはいけません。なぜなら、組織がシステムが侵害されていることを知っていて、侵害の継続を許可している場合、攻撃者が侵害されたシステムを使用して他のシステムを攻撃すると、責任を問われる可能性があるからだそうです。封じ込めが遅れると、攻撃者が不正アクセスをエスカレートしたり、他のシステムを危険にさらしたりする可能性があるため、封じ込め戦略は危険が伴うようです。
封じ込めに関するもう1つの潜在的な問題は、一部の攻撃が封じ込められたときに追加の損傷を引き起こす可能性があることだそうです。たとえば、侵害されたホストは、別のホストに定期的にpingを実行する悪意のあるプロセスを実行する可能性があります。侵害されたホストをネットワークから切断することによってインシデント対応者がインシデントを封じ込めようとすると、後続のpingは失敗し、その失敗の結果として、悪意のあるプロセスがホストのハードドライブ上のすべてのデータを上書きまたは暗号化する可能性があります。よって、対応者は、ホストがネットワークから切断されたという理由だけで、ホストへのさらなる損傷が防止されたと思い込んではならないわけです。
ログ管理の観点からは、封じ込め戦略を立てるためのリソースの損傷や被害状況の把握に関係するログを活用することになります。その他にも、判断のもとになる情報の入手先としても、ログからの情報は必要になります。
② エビデンスの収集と取扱い (Evidence Gathering and Handling)
『NIST.SP.800-61r2』の3.3.2 Evidence Gathering and Handlingには、インシデント時にエビデンスを収集する主な理由は、インシデントを解決することですが、法的手続きのためにエビデンスが必要になることもあり、このような場合、漏洩したシステムを含むすべてのエビデンスがどのように保存されたかを明確に文書化することが重要だとしています。エビデンスが人から人へと移される場合には、証拠保全フォームにその詳細が記載され、各当事者の署名が必要で、エビデンスは常に説明できるようにしなければならないとのことです。
すべてのエビデンスについて、以下のような詳細なログを残しておく必要があるそうなので抜粋しました。
● 識別情報(例:コンピュータの設置場所、シリアル番号、モデル番号、ホスト名、メディアアクセスコントロール(MAC)アドレス、IPアドレスなど)
● 調査中に証拠品を収集、または取り扱った各個人の氏名、役職、電話番号
● 証拠品を取り扱った各出来事の日時(タイムゾーンを含む)
● エビデンスが保管された場所
コンピュータリソースからのエビデンス収集にはいくつかの課題があり、一般的には、インシデントが発生した可能性を疑った時点で、対象となるシステムからエビデンスを収集することが望ましいとのことです。多くのインシデントは動的にイベントの連鎖を引き起こすので、初期状態のシステムのスナップショットは、この段階で取ることのできる他のほとんどのアクションよりも、問題とその原因を特定するのに役立つかもしれません。というのも、証拠能力の観点からは、インシデント対応者やシステム管理者などが、調査中にマシンの状態を誤って変更した後にスナップショットを取得するよりも、そのままの状態でシステムのスナップショットを取得する方がはるかに優れているらしいです。
ユーザとシステム管理者は、エビデンスを保全するために取るべき手順を知っておく必要があるとのことです。
参考資料:Guide to Integrating Forensic
Techniques into Incident
Response (Special Publication 800-86)
③ 攻撃しているホストの特定 (Identifying the Attacking Hosts)
『NIST.SP.800-61r2』の3.3.3 Identifying the Attacking Hostsには、インシデント処理の過程で、システム所有者などが、攻撃したホストを特定したい、あるいは特定する必要がある場合があり、このような情報は重要だとしています。
とはいえ、インシデント対応者は通常、封じ込め、撲滅、および復旧に集中すべきであり、攻撃ホストの特定は、時間のかかる無駄なプロセスであり、チームの主要な目標であるビジネスへの影響の最小化の達成を妨げる可能性があるとのことです。
以下の項目では、攻撃ホストの特定のために最も一般的に行われる活動についての説明があり抜粋しました。
■ 攻撃側ホストのIPアドレスの確認
不慣れなインシデント対応者は、攻撃しているホストのIPアドレスに注目してしまうことがよくあります。対応者は、そのアドレスへの接続性を確認することで、そのアドレスが偽装されていないことを検証しようとするかもしれませんが、これは単に、そのアドレスのホストがリクエストに応答するかしないかを示しているに過ぎません。たとえば、ホストが ping や tracerout を無視するように設定されている場合もありますが、応答しないからといってそのアドレスが実在しないとは限りません。また、攻撃者が受信したアドレスは、すでに他の人に再割り当てされている動的アドレスである可能性もあります。
■ 検索エンジンによる攻撃ホストの調査
攻撃の発信元と思われるIPアドレスを使用してインターネット検索を行うと、類似の攻撃に関するメーリングリストのメッセージなど、攻撃に関する詳細な情報が得られる場合があります。
■ インシデントデータベースの利用
あるグループ団体は、さまざまな組織からインシデントデータを収集し、インシデントデータベースに統合しています。このような情報共有は、トラッカーやリアルタイムのブラックリストなど、さまざまな形で行われることがあります。また、組織が独自のナレッジベースや課題追跡システムで関連する活動をチェックすることもできます。
■ 攻撃者と思われる通信チャネルの監視
インシデント対応者は、攻撃側のホストが使用する可能性のある通信チャネルを監視することができます。たとえば、多くのボットは、主要な通信手段としてIRC (Internet Relay Chat)を使用します。また、攻撃者は特定のIRCチャンネルに集まり、自分の侵害を自慢したり、情報を共有したりすることがありますが、インシデント対応者は、このような情報を入手しても、それを事実としてではなく、潜在的な手がかりとしてのみ扱うべきです。
ここでも、攻撃側ホストのIPアドレスや、攻撃側のホストが使用する可能性のあるチャネルなどの情報を得るために、ログが活躍します。攻撃しているホストを特定するためには、ネットワーク機器やネットワーク監視などのセキュリティツールのログが有効になります。
④ 根絶と復旧 (Eradication and Recovery)
『NIST.SP.800-61r2』の3.3.4 Eradication and Recoveryには、インシデントが収束した後は、マルウェアの削除や侵入されたユーザアカウントの無効化など、インシデントの構成要素を排除し、悪用されたすべての脆弱性を特定してリスクを軽減するために、根絶作業が必要になることがあるとしています。
インシデントによっては、根絶が必要ない場合や、復旧時に実行される場合もありますが、根絶の際には、組織内の影響を受けたすべてのホストを特定し、それらを修復できるようにすることが重要です。
復旧時には、管理者はシステムを通常の運用状態に戻し、システムが正常に機能していることを確認し、必要に応じて同様のインシデントを防止するため脆弱性を修正します。
復旧には、クリーンなバックアップからのシステムの復元、ゼロからのシステムの再構築、侵害されたファイルのクリーンなバージョンへの置き換え、パッチのインストール、パスワードの変更、ネットワーク周辺のセキュリティ強化のためのファイアウォールのルールセット、境界ルーターのアクセスコントロールリストなどの作業が必要になります。
また、システムログの記録やネットワークの監視を強化することも、復旧作業の一環として行われます。一度攻撃が成功してしまうと、同じリソースが再び攻撃されたり、組織内の他のリソースが同様の方法で攻撃されたりすることがよくあるようです。
根絶と復旧は、修復ステップに優先順位をつけられるよう、段階的なアプローチで行う必要があります。大規模なインシデントの場合、復旧には数ヶ月かかることもあります。
初期のフェーズでは、今後のインシデントを防ぐために、数日から数週間の比較的短期間で価値の高い変更を行い、全体的なセキュリティを向上させることを目的とします。後半のフェーズでは、インフラの変更などより長期的な変更と、企業の安全性を可能な限り維持するための継続的な作業に重点を置くべきとのことです。
ログ管理の観点からは、復旧作業の一環としてシステムログの記録やネットワークの監視を強化があげられていますが、復旧時にログ管理の設定内容を見直し、インシデントに関係したところの監視の強化や、ログ取得内容の改善などにより、同じインシデントが再び起きないよう、または、起きても最小限の被害にくい止めることができるようにすることがポイントだとわかります。
根絶の意味は、一度だけの対処ではなく、できれば永遠に起きないようにするための対処が必要だということです。
事後対応(Post-Incident Activity)
『NIST.SP.800-61r2』の最後、4つ目のカテゴリーは、Post-Incident Activity(事後対応)です。
インシデントの根絶、復旧が完了すると、その事後処理として、そこで学んだ教訓や、インシデントデータ、エビデンスなどどのように保持し、活用していくかが重要になります。

① 学んだ教訓 (Lessons Learned)
『NIST.SP.800-61r2』の3.4.1 Lessons Learnedでは、インシデント レスポンスの最も重要な部分の一つは、最も省略されがちな「学習と改善」であり、インシデント対応チームは、新たな脅威、技術の向上、そして学んだ教訓を反映して進化する必要があるとしています。
大規模なインシデントが発生した後、あるいはリソースが許す限り小規模なインシデントが発生した後でも、関係者全員による「学んだ教訓」についてのミーティングを定期的に開催することは、セキュリティ対策やインシデント対応プロセス自体の改善に非常に有効とのことです。1回の教訓のミーティングで複数のインシデントをカバーしてよく、このミーティングは、何が起こったのか、介入するために何が行われたのか、介入がどの程度うまくいったのかを検討することにより、インシデントに関して終息を達成する機会を提供します。このミーティングは、インシデントが終わってから数日以内に行われるべきだそうです。
ミーティングでは、以下のような質問に答える必要があるとのことなので、抜粋しました。
● 正確に、何が、どのタイミングで起こったのか?
● スタッフと経営陣はインシデントに対処する上でどのような成果を上げたか?文書化された手順は守られたか?それは適切だったか?
● どのような情報がより早く必要だったか?
● 復旧を妨げる可能性のある手順や行動はあったか?
● 次に同様のインシデントが発生した場合、スタッフと経営陣はどんな異なる方法で行うか?
● 他の組織との情報共有はどのように改善できたか?
● どのような是正措置をとれば、将来的に同じようなインシデントを防ぐことができるか?
● 同様のインシデントを検知するために、今後どのような前兆や兆候に注意すべきか?
● 将来のインシデントを検知、分析、軽減をするために、どのような追加ツールまたはリソースが必要か?
小規模なインシデントであれば、インシデント発生後の分析は限定的なもので済みますが、広く懸念されている新しい攻撃方法によって実行されたインシデントは例外となります。深刻な攻撃が発生した後は、情報共有のための仕組みを提供するために、チームや組織の境界を越えた事後ミーティングを開催することは、とても価値のあることのようです。このようなミーティングを開催する際に考慮すべき点は、適切な人材を参加させることです。分析対象のインシデントに関与した人を招待することが重要であるだけでなく、今後の協力関係を促進するために誰を招待すべきかを検討することが賢明とのことです。
また、ミーティングの成否は議題にもよりますが、提案されたトピックはもちろん、ミーティングの前に参加者から期待やニーズについての意見を集めることで、参加者のニーズが満たされる可能性が高くなります。また、ミーティングの開始前または開始中に議事進行のルールを定めることで、混乱や意見の相違を最小限に抑えることができます。また、グループファシリテーションに長けたモデレーターが1人以上いることで、高い効果が期待できます。最後に、主な合意事項やアクション項目を文書化し、ミーティングに参加できなかった人に伝えることも重要とのことです。
ミーティングで学んだ教訓には他にも利点があり、ミーティングでの報告は、経験豊富なチームメンバーがどのようにインシデントに対応しているかを示すことで、新しいチームメンバーをトレーニングするための良い材料となります。インシデント対応の方針や手順を更新することも、教訓のプロセスの重要な部分です。インシデントの処理方法を事後的に分析すると、手順に欠けている部分や不正確な部分が明らかになり、変更のきっかけになることが多いです。IT技術は変化し、人員も変わるため、インシデント対応チームは、インシデントを処理するためのすべての関連文書と手順を適宜定期的に見直す必要があるようです。
インシデント後のもう一つの重要な活動は、インシデントごとにフォローアップ・レポートを作成することであり、これは将来的に非常に価値のあるものとなるようです。このレポートは、類似のインシデントを処理する際の参考資料となります。システムのログデータなど、タイムスタンプ付きの情報を含むイベントの正式な年ごとの履歴表を作成することは、法的な理由から重要であり、インシデントが引き起こした損害の金額を見積もることと同様に重要です。フォローアップ・レポートは、記録保持ポリシーで指定された期間、保存される必要があるとのことです。
こうした学んだ教訓をもとに、ログ管理システムについても、その運用方法や、設定内容などを改善していくことが必要です。ログは、改善の効果測定にも役立つ場合があります。
インシデントの兆候をいち早く察知し、即座にアラートして、その後の分析も迅速に行く事ができるようにログ管理システムを改善すれば、インシデント発生時の被害を最小限に抑えることが期待できます。
② 収集されたインシデントデータの使用 (Using Collected Incident Data)
『NIST.SP.800-61r2』の3.4.2 Using Collected Incident Dataでは、教訓として学んだ活動では、各インシデントに関する一連の客観的および主観的なデータを作成する必要があり、収集されたインシデントデータは、時間の経過とともに、いくつかの点で役に立つはずだとしています。
特に関与した総時間と費用のデータは、インシデント対応チームへの追加資金を正当化するために使用することができ、インシデントの特徴を調査することで、システム的なセキュリティの弱点や脅威、インシデントの傾向の変化などを示すことができます。このデータは、リスクアセスメントのプロセスに戻すことができ、最終的には追加コントロールの選択と実施につながるとのことです。
また、データの良い使い方として、インシデント対応チームの成功度を測ることができ、インシデントデータが適切に収集・保存されていれば、インシデント対応チームの成功または活動を示すいくつかの指標が得られるはずだとのことです。
そして、インシデントデータを収集することで、インシデント対応能力の変化が、効率の向上、コストの削減などチームのパフォーマンスに対応する変化をもたらすかどうかを判断することができるようです。
組織は、単にデータがあるから収集するのではなく、実用性のあるデータを収集することに重点を置くべきで、重要なのは、その数値が組織のビジネスプロセスに対する脅威をどのように表しているかを理解することです。組織は、レポート要件と、データから期待される投資収益率に基づいて、どのようなインシデントデータを収集するか、たとえば、新たな脅威を特定し、それが悪用される前に関連する脆弱性を緩和することなどを決定する必要があるとのことです。
インシデント関連データで考えられる評価指標は以下の通りで、抜粋しました。
■ 処理されたインシデントの数
より多くのインシデントを処理することが必ずしも良いとは限りません。たとえば、インシデント対応チームの活動が原因ではなく、ネットワークやホストのセキュリティの制御管理が改善されたことにより、処理されるインシデントの数が減少することがあります。処理されたインシデントの数は、インシデント対応チームが行わなければならなかった作業の相対的な量を示す指標として捉えるのが最善であり、作業の質を示す他の指標と総合的に考えた場合を除き、チームの質を示す指標ではありません。インシデントカテゴリーごとに、個別のインシデントの件数を作成することは効果的です。また、サブカテゴリーを使うことで、より多くの情報を得ることができます。たとえば、インサイダーによるインシデントの件数が増加している場合には、人員の身元調査やコンピューティングリソースの不正使用に関するポリシー規定の強化や、侵入検知ソフトウェアをより多くの内部ネットワークやホストに配備するなど内部ネットワークのセキュリティ管理の強化を促すことができます。
■ インシデントごとの時間
インシデントごとに、いくつかの方法で時間を測定することができます。
- インシデントの作業に費やした労働力の総量
- インシデントの開始から、インシデントの発見、最初の影響評価、インシデント処理プロセスの各段階(封じ込め、復旧など)までの経過時間
- インシデント対応チームがインシデントの最初の報告に対応するのに要した時間
- 経営陣および必要に応じて適切な外部機関にインシデントを報告するのに要した時間
■ 各インシデントの客観的な評価
解決したインシデントへの対応は、それがどれだけ効果的であったかを分析することができます。以下は、インシデントの客観的な評価を行うための例です。
- ログ、フォーム、レポート、およびその他のインシデント文書が、確立されたインシデント対応ポリシーおよび手順に準拠しているかどうかを確認すること
- インシデントの前兆や兆候が記録されているかを確認し、インシデントがどれだけ効果的に記録・特定されたかを判断すること
- インシデントが検出される前に損害を与えたかどうかを判断すること
- インシデントの実際の原因が特定されたかどうかを判断し、攻撃のベクトル、悪用された脆弱性、標的となったまたは被害を受けたシステム、ネットワーク、およびアプリケーションの特性を特定すること
- 当該インシデントが過去のインシデントの再発であるかどうかを判断すること
- インシデントによる推定金銭的損害額の算出(インシデントによりマイナスの影響を受けた情報や重要なビジネスプロセスなど)
- 初期の影響評価と最終的な影響評価の違いを測定すること
- あるとすれば、どの対策がインシデントを防止できたかを特定すること
各インシデントの主観的評価
インシデント対応チームのメンバーは、自分自身のパフォーマンスだけでなく、他のチームメンバーやチーム全体のパフォーマンスの評価を求められることがあります。また、攻撃を受けたリソースの所有者が、インシデントが効率的に処理されたと考えているかどうか、結果は満足のいくものだったかどうかを判断するために、貴重な情報源となります。
チームの成功を測定するためにこれらの指標を使用するだけでなく、組織は、インシデント対応プログラムを定期的に監査することも有用です。監査によって、問題や欠陥が特定され、それを修正することができます。
インシデント対応の監査では、少なくとも以下の項目を、適用される規制、ポリシー、および一般に認められた慣行に照らして評価する必要があるそうなので、次に抜粋しました。
● インシデント対応のポリシー、計画、および手順
● ツールおよびリソース
● チームモデルおよび構造
● インシデント対応者のトレーニングと教育
● インシデントの文書化とレポート
● このセクションで前述した成功の尺度
③ エビデンスの保持 (Evidence Retention)
『NIST.SP.800-61r2』の3.4.3 Evidence Retentionでは、組織は、インシデントのエビデンスをどのくらいの期間保持すべきかについてのポリシーを作成する必要があるとしています。
ほとんどの組織は、インシデントが終了した後、数ヶ月または数年にわたってすべてのエビデンスを保持することを選択します。
ポリシー作成の際には、以下の要因を考慮する必要があるとのことなので、抜粋しました。
■ 起訴
攻撃者が起訴される可能性がある場合は、すべての法的措置が完了するまでエビデンスを保持する必要がある場合があります。場合によっては、これに数年かかることもあります。さらに、現在は重要ではないと思われるエビデンスも、将来的には重要になる可能性があります。たとえば、攻撃者がある攻撃で収集した知識を利用して、より深刻な攻撃を後に実行することができた場合、最初の攻撃のエビデンスが、2回目の攻撃がどのようにして達成されたかを説明する鍵となることがあります。
■ データの保持
ほとんどの組織は、特定の種類のデータをどのくらいの期間保存できるかを示すデータ保持に関するポリシーを持っています。たとえば、ある組織では、電子メールのメッセージは180日間のみ保持することになっています。ディスクイメージに何千通もの電子メールが含まれている場合、組織は、特に必要でない限り、そのイメージを180日以上保管しないようにします。
■ コスト
エビデンスとして保管されるハードドライブ、侵害されたシステムなどのオリジナルのハードウェアや、ディスクイメージを保持するために使用されるハードドライブやリムーバブルメディアは、一般的に個々に安価であっても、組織がこのようなコンポーネントを多数、何年も保管する場合、そのコストは相当なものになる可能性があります。また、組織は、保存されたハードウェアやメディアを使用できる機能的なコンピュータを保持する必要があります。
エビデンスの多くはログデータです。ログ管理において、ログの保持期間や、証拠保全、保管メディアの選定など、重要なポイントが多く存在します。
コストとのバランスですが、特にエビデンスは改ざんされない状態で保管されていたかどうかが必須の条件なため、証拠保全が担保されているログ管理システムの構築が必要となります。
確認・推奨事項
インシデント レスポンスの手順に沿って行動するには、ログ管理が重要なポイントになります。
(1) インシデント レスポンス チェックリスト
『NIST.SP.800-61r2』の3.5 Incident Handling Checklistにある以下のチェックリストは、インシデントの対応で実行される主な手順を示しています。
実行される実際の手順は、インシデントのタイプと個々のインシデントの性質によって異なる場合があります。たとえば、対応者が兆候の分析(ステップ1.1)に基づいて何が起こったかを正確に知っている場合、アクティビティをさらに調査するためにステップ1.2または1.3を実行する必要がない場合があります。チェックリストは、実行する必要のある主要なステップに関するガイドラインを対応者に提供しますが、常に従う必要のある手順の正確な順序を指示するものではありません。
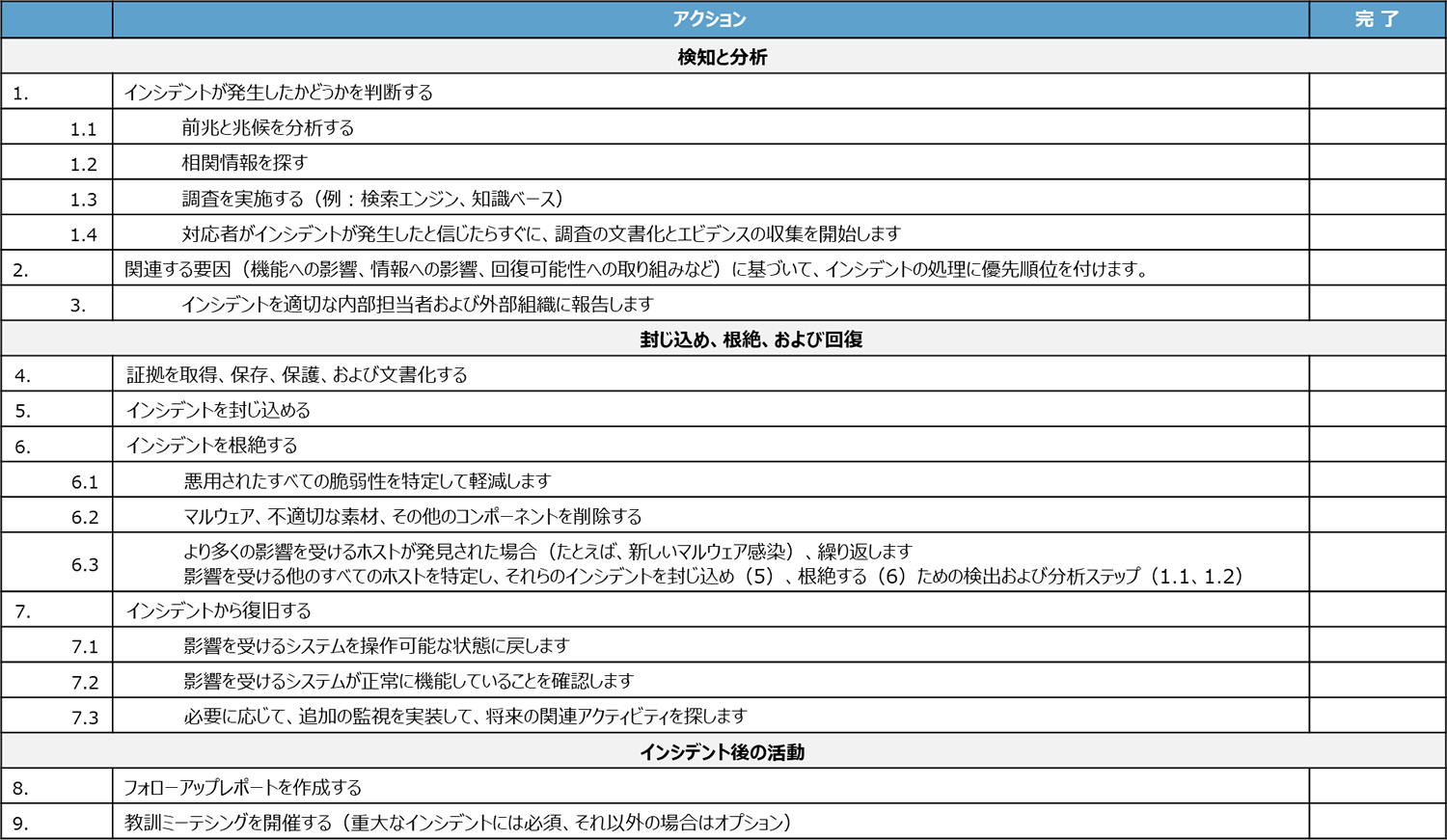
このリストは、インシデント レスポンスにおいて、インシデントの発生が懸念されてから行うべき行動が簡潔にまとまられています。
インシデントの規模に応じて、すべて実行する必要はないかもしれませんが、こうした手順を踏まえ行動することにより、効率的に迅速に対応しリスクを最小限に抑える効果が期待できます。
それぞれの項目について、その行動を実践するためには、ログ管理システムが重要な役割を果たすであろうことは容易に推測できます。つまり、最適なログ管理システムは、インシデント レスポンスに大いに貢献します。
(2) 推奨事項
『NIST.SP.800-61r2』の3.6 Recommendationsには、インシデントを処理するための主な推奨事項が記載されており、以下に抜粋しました。
■ インシデント対応時に有用と思われるツールやリソースを入手する
チームは、さまざまなツールやリソースがすでに利用可能であれば、インシデントをより効率的に処理することができます。たとえば、連絡先リスト、暗号化ソフトウェア、ネットワーク図、バックアップデバイス、デジタルフォレンジックソフトウェア、ポートリストなどがあります。
■ ネットワーク、システム、およびアプリケーションが十分に安全であることを確認することで、インシデントの発生を防ぐ
インシデントを防止することは、組織にとって有益であり、また、インシデント対応チームの作業負荷を軽減することにもつながります。定期的にリスクアセスメントを実施し、特定されたリスクを受容可能なレベルまで低減することは、インシデントの数を減らすのに有効です。また、ユーザ、ITスタッフ、および経営陣によるセキュリティポリシーと手順の認識も非常に重要です。
■ いくつかのタイプのセキュリティ・ソフトウェアが生成するアラートによって、前兆や兆候を特定する
侵入検知・防止システム、アンチウイルス・ソフトウェア、ファイル整合性チェック・ソフトウェアは、インシデントの兆候を検知するのに有効です。それぞれのソフトウェアは、他のソフトウェアでは検知できないインシデントを検知できる可能性があるため、複数のコンピュータ・セキュリティ・ソフトウェアを使用することを強くお勧めします。また、第三者による監視サービスも有用です。
■ 外部の人間がインシデントを報告できる仕組みを構築する
たとえば、ある組織のユーザが自分たちを攻撃していると思っている場合など、外部の関係者が組織にインシデントを通知したい場合があります。組織は、外部の当事者がこのようなインシデントを報告するために使用できる電話番号と電子メールアドレスを公開する必要があります。
■ すべてのシステムにベースラインレベルのログおよび監査を要求し、すべての重要なシステムにはより高いベースラインレベルを要求する
オペレーティング・システム、サービス、およびアプリケーションからのログは、特に監査が有効になっている場合、インシデントの分析において価値をもたらすことがよくあります。ログには、どのアカウントがアクセスされ、どのようなアクションが実行されたかなどの情報が含まれます。
■ ネットワークとシステムのプロファイリングを作成する
プロファイリングは、予想される活動レベルの特性を測定し、パターンの変化をより簡単に識別できるようにします。プロファイリング・プロセスが自動化されていれば、予想されるアクティビティ・レベルからの逸脱を検知し、管理者に迅速に報告することができるため、インシデントや運用上の問題をより早く発見することができます。
■ ネットワーク、システム、およびアプリケーションの正常な動作を理解する
正常な動作を理解しているチームメンバーは、異常な動作をより簡単に認識することができます。このような知識は、ログエントリやセキュリティアラートを確認することで得られます。対応者は、典型的なデータに慣れ親しみ、異常なエントリを調査することでより多くの知識を得ることができます。
■ ログの保持ポリシーを作成する
インシデントに関する情報は、複数の場所に記録されている可能性があります。古いログ・エントリには、偵察活動や同様の攻撃の過去の事例が記録されている可能性があるため、ログ・データをどのくらいの期間維持すべきかを規定したログ保持ポリシーを作成し、実施することは、分析に非常に役立ちます。
■ イベント相関を実行する
インシデントのエビデンスは、複数のログに記録されている場合があります。複数のソース間でイベントを相関させることは、インシデントに関して入手可能なすべての情報を収集し、インシデントが発生したかどうかを検証する上で非常に有効です。
■ すべてのホストのクロックを同期させる
イベントを報告するデバイスのクロック設定が一致していない場合、イベント相関はより複雑になります。また、クロックの不一致は、証拠能力の観点からも問題となります。
■ 情報の知識ベースを維持・使用する
一元化されたナレッジベースは、一貫した維持可能な情報源となります。知識ベースには、過去のインシデントの前兆や兆候に関するデータなど、一般的な情報を含めるべきです。
■ チームがインシデントの発生を疑った時点で、すべての情報の記録を開始する
インシデントが検知されてから最終的に解決するまでのすべてのステップを文書化し、タイムスタンプを付ける必要があります。このような情報は、法的な訴追が行われた場合、法廷での証拠として役立ちます。また、実行した手順を記録することで、より効率的で体系的な、ミスの少ない問題処理が可能になります。
■ インシデントデータを保護する
インシデントデータには、脆弱性、セキュリティ侵害、不適切な行為を行った可能性のあるユーザなどの機密情報が含まれていることがよくあります。チームは、インシデントデータへのアクセスが論理的にも物理的にも適切に制限されていることを確認する必要があります。
■ 関連する要因に基づいて、インシデントの処理に優先順位をつける
リソースの制限があるため、インシデントは先着順に処理すべきではありません。代わりに、組織は、インシデントの機能的および情報的な影響、インシデントからの復旧の可能性などの関連要因に基づいて、チームがどのくらい迅速にインシデントに対応しなければならないか、どのようなアクションを実行すべきかをまとめた書面によるガイドラインを確立する必要があります。これにより、インシデント対応者の時間が節約され、経営陣やシステムオーナーに対して行動の正当性を示すことができます。また、組織は、チームが指定された時間内にインシデントに対応できない場合のために、エスカレーションプロセスを確立する必要があります。
■ 組織のインシデント対応方針に、インシデント報告に関する規定を盛り込む
組織は、どのようなインシデントを、いつ、誰に報告しなければならないかを規定する必要があります。最も一般的に通知されるのは、CIO、情報セキュリティ責任者、地域の情報セキュリティ責任者、組織内の他のインシデント対応チーム、およびシステム所有者です。
■ インシデントを収束させるための戦略と手順を確立する
インシデントを迅速かつ効果的に収束させ、ビジネスへの影響を抑えることが重要です。組織は、インシデントの封じ込めにおいて許容できるリスクを定義し、それに応じて戦略と手順を策定する必要があります。封じ込め戦略は、インシデントの種類に応じて変える必要があります。
■ 確立されたエビデンス収集と処理の手順に従うこと
チームは、すべてのエビデンスがどのように保存されたかを明確に文書化する必要があります。エビデンスはいつでも説明できるようにしておきます。チームは、法務担当者や法執行機関と証拠品の取り扱いについて話し合い、その話し合いに基づいて手順を作成します。
■ システムから揮発性のデータをエビデンスとして収集する
これには、ネットワーク接続のリスト、プロセス、ログインセッション、開いているファイル、ネットワークインターフェイスの設定、メモリの内容などが含まれます。信頼できるメディアから慎重に選択したコマンドを実行することで、システムのエビデンスを損なうことなく必要な情報を収集することができます。
■ ファイルシステムのバックアップではなく、完全なフォレンジックディスクイメージでシステムのスナップショットを取得する
ディスクイメージは、サニタイズされたライトプロテクトまたはライトワンスメディアに作成する必要があります。このプロセスは、調査および証拠としての目的では、ファイルシステムのバックアップよりも優れている。イメージは、オリジナルのシステム上で分析を行うよりも、イメージを分析する方がはるかに安全であるという点でも価値があります。
■ 重大インシデントの後には、教訓ミーティングを開催する
教訓ミーティングは、セキュリティ対策やインシデント処理プロセス自体の改善に非常に役立ちます。
これらの推奨事項の多くは、ログ管理システムの構築においても十分参考にすべき内容が多く含まれております。
ログ管理システムによって、インシデント検知を迅速に行う仕組みを整備したり、ログを有効活用して、予兆判断してインシデントを未然に防いだり、監視対象の強化に役立てたりとインシデント レスポンスにおいても、たいへん役立つことが期待できます。
このページは、NISTのComputer Security Incident Handling Guide (Special Publication 800-61 Revision 2)の内容をもとに編集しておりますが、完全に正確であることを保証するものではありません。 *本ページ内容の転記流用を一切禁止します。